Experiencias Xcaret Logistics
A large-scale passenger-transport orchestration platform built for fully committed demand under hard operational constraints — planning, execution and real-time control across the full transport lifecycle.

Operating Context and Experiencias Xcaret Transformation
Experiencias Xcaret is the largest integrated tourism operator in Latin America, based in the Riviera Maya. It runs seven theme parks and welcomes around 4 million visitors per year, or roughly 12,000 per day, while directly employing more than 17,000 people and supporting over 65,000 families indirectly across its wider ecosystem of roughly 500 hotels, transport providers, resellers, and on-site service operations
Around 2016–2017, the organization was undergoing a major technology renewal program covering core systems modernization, cloud migration, and hyperscaler-aligned architecture. Logistics was identified as a critical bottleneck. Multiple top-tier international providers were engaged — including specialists in large-scale transportation and major global theme park operations. The conclusion was consistent: the problem did not fit existing operational models. No out-of-the-box solution was available.
The underlying structure pointed to a complex variant of the Vehicle Routing Problem (VRP), with additional constraints and real-time dynamic behaviors that made it significantly harder than standard formulations — an NP-complex problem under live operational conditions.
Mission Critical alike problem (Fully Committed Demand with Zero Flexibility)
The transport system operated under a demand model that was entirely externally imposed and non-negotiable.
Tickets were sold through a distributed network — hotels, resellers, and street-level sales — with no coordination with operational capacity. Any seller could commit a service independently, with no pre-sale validation, no capacity check, and no system awareness. Each ticket defined a fixed pickup time at a specific location at the moment of sale. That commitment could not be adjusted, deferred, or replaced. The system had no demand visibility until it was already locked in
At the same time, service constraints were strict:
- each vehicle had a fixed seating capacity (no standing passengers),
- and each location was served as a single, non-repeatable event at the committed time (no second pass).
Semifléxible objectives with Multi-Constraint Structure
Semi-Flexible Objectives and Multi-Constraint Structure
On top of this rigid demand model, the system had to continuously balance a large set of interacting and frequently conflicting.
These constraints included, among others:
- Pickup punctuality vs arrival punctuality
- Minimizing number of vehicles vs assigning correct vehicle types to specific routes, hotels, or services.
- Number of stops vs total journey duration
- Minimize the use of transfer center vs maximize vehicle occupancy
- Avoid congestion on parks arrival or during the route
- Minimize fuel consumption vs panoramic route (increase extra sales on board)
The constraints were not purely hard or purely soft.
- Some were hard constraints (e.g. capacity, route feasibility, no standing passengers)
- Others were semi-flexible constraints, influenced by operational policies, service expectations, or contextual priorities
More critically, their relative importance was dynamic: there was no fixed weighting system. The cost of violating or optimizing a given constraint shifted continuously based on the current operational state. Two solutions with very similar metrics could be evaluated very differently depending on circumstances, timing, and operational perception.
Combinatorial Structure and Propagation
At the core of the system, decisions were resolved as assignments of 12.000 thousand combinations of:
passenger — vehicle — route
For each assignment, the planning engine evaluated approximately 60 million feasible configurations, optimizing across all active objectives simultaneously.
The system also had to handle continuous disruption: no-show passengers, last-minute sales, and traffic incidents required real-time replanning within the same combinatorial space.
Crucially, no decision was isolated. Each assignment consumed capacity — seats, time windows, route structure — directly reshaping the feasible space for every subsequent decision. A single change could cascade across multiple assignments, each requiring re-evaluation across its own multi-million configuration space, while simultaneously affecting the relative satisfaction of competing objectives.
Under high-pressure conditions — group bookings, sudden demand spikes, operational disruptions — these cascading effects amplified rapidly across the network.
Technical Solution Architecture: JUBAP.Net © xSeil as a Full Logistics Intelligence Platform
The technical solution was not conceived as a standalone routing or optimization engine. It was designed as a full logistics intelligence platform spanning the end-to-end transport lifecycle: data acquisition, normalization, planning, rental estimation, real-time monitoring, dynamic route adjustment, transfer coordination, field execution, and managerial decision support. In the project documentation, xSeil is explicitly positioned as a General Planning and Logistics Control System for Xtours, not as a narrow VRP tool.
This architectural approach was not accidental. It was grounded in more than a decade of prior experience designing and operating large-scale logistics and operational intelligence systems, including the core digital architecture of the Chicontepec megaproject—an infrastructure designed for a significantly larger scale of operations. already demonstrated a critical principle: operational intelligence depends on end-to-end control of data, its structure, and its quality.
The client was therefore approached with a different proposition: the design of a complete logistics platform, capable of integrating fragmented systems, normalizing inconsistent operational data, and ensuring that planning decisions were grounded in reliable, real-time, and operationally coherent information.
In this sense,JUBAP.Net © xSeil was not only solving a routing problem—it was establishing the data and control foundation required to make such a problem solvable in practice.
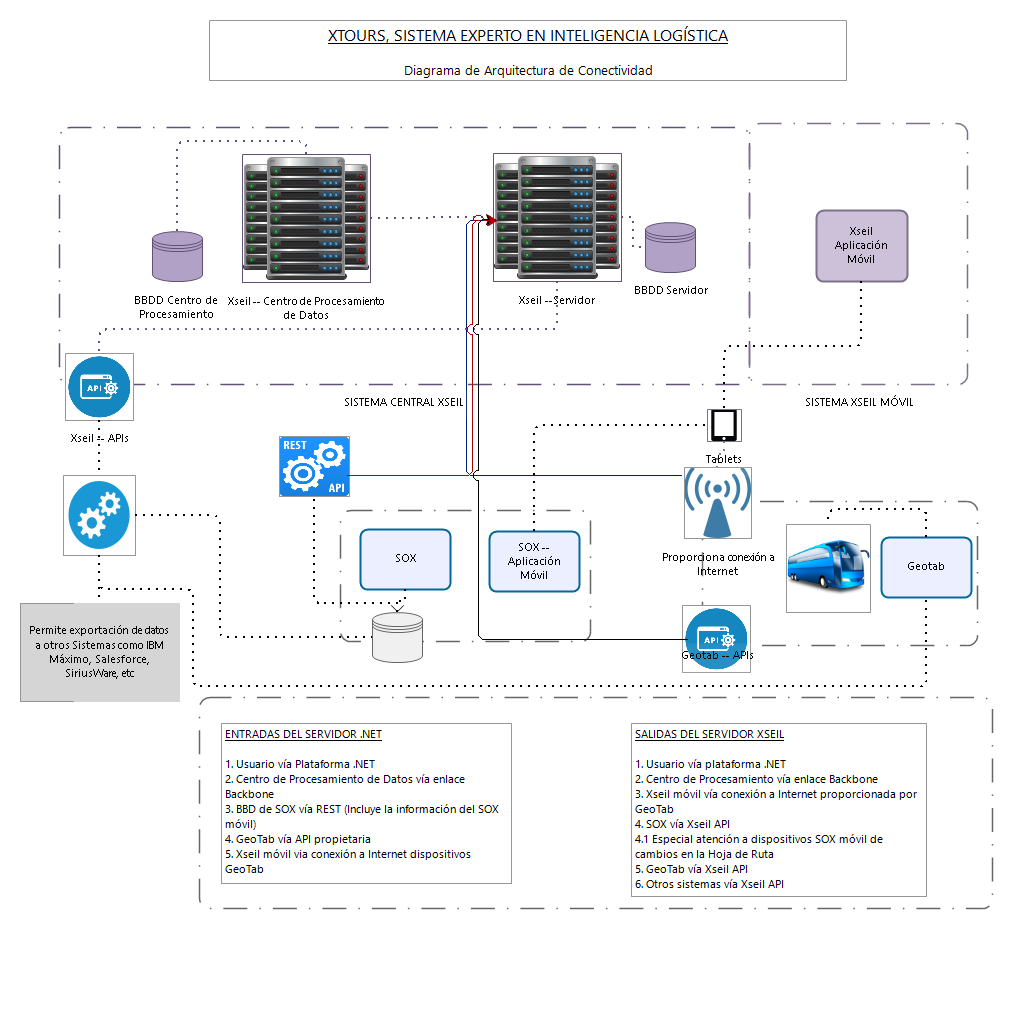
1. Overall Architectural Structure
At a high level, the platform was organized into two main execution environments:
- a central web-based operation and control subsystem
- a real-time mobile route subsystem for field execution
The core architecture was specified around:
- Linux / POSIX server environment
- Python 3 for large-scale processing and algorithmic logic
- Django as the web application framework
- PostgreSQL as the main data platform for large data volumes, complex processing, and future scalability
The central subsystem was designed to provide shared access across the organization through a web environment, with support for up to 250 concurrent users in the first year. The mobile subsystem extended the platform into the field through Android and iOS devices for guides, drivers, and operational users.
In architectural terms, JUBAP.Net © xSeil can be understood as a layered system:
- Integration and data normalization layer
- Operational master data and control layer
- Planning and optimization layer
- Execution and monitoring layer
- Dynamic adjustment and coordination layer
- Managerial intelligence and reporting layer
2. Integration and Data Normalization Layer
A critical architectural element was the integration layer.
JUBAP.Net © xSeil did not operate on clean, internally generated data. It depended on continuous ingestion of operational data from SOX and other operational sources, later extended toward SOA-style connectivity rather than direct database access.
The required interfaces covered a broad operational model, including:
- units
- hotels
- services
- hotel routes
- pickup schedules
- reservations
- operations
- operation details
- return operations
- mobile operation records
This layer performed not only connectivity but also validation and normalization. The documentation makes explicit that JUBAP.Net © xSeil would reject inconsistent operational structures, including:
- duplicate hotel names
- duplicate or invalid vehicle identities
- reservations not linked to valid hotel, park, and pickup configurations
- mismatches between manual planning and reservation data
In practice, this layer functioned as a middleware / ETL / cleansing layer between fragmented transactional systems and the logistics intelligence engine. This is architecturally important because planning quality depended directly on data quality, and the platform was explicitly designed to absorb, clean, and structure inconsistent operational inputs before optimization. The technical annex also defines normalization and ETC-style communication with other systems as a formal component type of the solution.
3. Operational Master Data and Fleet Readiness Layer
On top of the integration layer, JUBAP.Net © xSeil maintained the operational structure required for planning and control.
This included catalogues and internal data structures for:
- vehicle types and vehicle categories
- available units and rented units
- hotels, routes, parks, services, and zones
- pickup hours and SLA tolerances
- transfer points, nodes, and geofences
- passengers and passenger groups
- times between points and boarding-time logic
- user, guide, and driver structures
- route sheets and operational roles
A particularly important subsystem was the preceptoría / fleet readiness layer, which tracked:
- maintenance status
- operational status
- service role of each unit
- unit availability for planning
- workshop-related conditions
- historical maintenance patterns and related reporting
This means the architecture already embedded the practical reality that planning could not be isolated from fleet readiness. Vehicle assignment quality depended not only on passenger demand, but also on maintenance state, private operation status, role configuration, and actual unit availability.
4. Planning and Optimization Layer
The core planning engine was only one layer of the wider platform.
This layer generated and evaluated alternative planning scenarios for Xtours operations, balancing load factor, punctuality, directness, travel structure, and vehicle policies. The documentation explicitly states that the system could generate different planning scenarios and evaluate them under a high number of rules and methods, exceeding one hundred operational rules in some descriptions.
Documented planning outputs included:
- unit list for service
- passengers transported by route
- factor of occupancy
- percentage of direct trips
- expected SLA compliance
- planning process time
The planning layer also included:
- rental estimation, projecting demand and suggesting third-party vehicle needs
- schedule optimization, proposing improved pickup schedules
- support for different service types and different planning parameters by service
- support for hotel blocks, dynamic transfer policies, ad hoc transfer centers, slow-transit hours, saturation logic, and special conditions such as wheelchair seating rules
Architecturally, this shows that the optimization layer was not a pure route solver. It was a configurable planning engine embedded in a broader operational model.
5. Execution and Real-Time Monitoring Layer
JUBAP.Net © xSeil was also designed as an execution-aware platform.
Field users — primarily guides and drivers — authenticated through mobile devices, validated assigned units, captured boarded passengers, and later received route changes or transfer instructions. Android and iOS clients were explicitly planned as part of the architecture, along with mobile connectivity, field validation of assignments, and automatic connectivity tests.
GeoTab integration provided:
- route and positioning data
- geofence events
- exceptions and operational monitoring inputs
This enabled the platform to compare:
- planned operation
- actual movement
- actual boarding
- actual punctuality
That comparison was surfaced through the Control Logístico intelligent screen, which displayed:
- map of the operating region
- real-time location of units
- passenger counts by hotel and by destination
- assigned units
- route visualization
- promised vs actual pickup times
- punctuality performance by unit
- direct vs transfer-based movements
So the system was not only computing plans overnight. It was creating a real-time feedback loop between planning, field execution, and operational control.
6. Dynamic Adjustment and Coordination Layer
A further architectural layer handled what happened after execution diverged from plan.
This included:
- estimated time of arrival logic across routes and pickup points
- dynamic route sheet updates in response to no-shows, go-shows, and operational incidents
- transfer center coordination for passenger exchanges between units
- reassignments for guides, drivers, and units
- copiloto / travel assistant logic to calculate target cruising speed and reduce congestion at park entrances
These modules are architecturally significant because they convert JUBAP.Net © xSeil from a planning platform into a closed-loop adaptive operating system.
The system was designed not only to plan, but to:
- detect deviations
- update route logic
- redistribute passengers
- coordinate transfers
- rebalance field execution
- protect punctuality and arrival flow in real time
That is a fundamentally different architecture from a static optimizer.
7. Managerial Intelligence and Reporting Layer
The final architectural layer converted execution data into management information.
The system included a managerial decision support module with reports and dashboards on:
- punctuality by unit, driver, route, hotel, and destination
- route compliance
- possible deviations from standard behavior
- vehicle speed compliance
- reassignment histories
- operational delays
- maintenance and rental-related indicators
This confirms that JUBAP.Net © xSeil was intended not only for operational dispatching, but also for governance, supervision, and managerial control.
8. Technical Runtime Characteristics
The documented technical stack evolved during the project.
In the main architecture and requirements documentation, the platform is consistently described around Python, Django, PostgreSQL, Linux, web services, and mobile clients.
In later production performance notes already reflected in your draft, the runtime behavior also included a more compute-intensive processing profile using elements such as:
- application-layer orchestration
- ORM/database interaction
- large in-memory processing
- multithreading
- statistical and optimization processing
Consolidated Architectural Interpretation
In enterprise architecture terms, JUBAP.Net © xSeil was a modular logistics intelligence platform composed of:
- a web-based command and control core
- a mobile execution layer
- a data integration and cleansing layer
- an operational master-data layer
- a planning and optimization engine
- a real-time monitoring layer
- a dynamic reconfiguration layer
- a managerial intelligence and reporting layer
Its purpose was to bridge fragmented systems, normalize inconsistent data, generate planning scenarios, monitor live execution, dynamically reconfigure routes and transfers, and support both field coordination and management control across the full transport operation lifecycle. It should therefore be understood not as a «VRP tool,» but as an integrated mission-critical logistics operating platform.
3. Managing VRP Complexity: A Stability-Driven, Pre-Agentic Approach
Conceptual Overview
Before detailing individual modules, it is important to clarify that the system did not approach the problem as a classical routing optimization task. Instead, it operated as a centralized, stability-driven allocation system, which can be interpreted retrospectively as pre-agentic, although this terminology was not used in the original implementation.
In the actual system, the core entities were not defined as «agents» or «clusters,» but as operational constructs such as reservations, groupings (agrupadores colaborativos), combinations (solution space exploration), and pickups (selected high-quality assignments). The agent-based interpretation is therefore conceptual, used here to explain behavior, not to describe the original code structure.
At runtime, planning was fully centralized. A single system evaluated the full state of the operation and made decisions globally, optimizing across all reservations simultaneously. There was no distributed or edge-based decision-making. However, the logic implicitly treated each reservation as an individual decision unit whose utility needed to be maximized under shared constraints.
At its core, the problem was not routing vehicles, but allocating constrained service quality (capacity, punctuality, route structure, transfer avoidance, vehicle type) across thousands of competing and partially cooperating reservations.
Each reservation (passenger) behaved as a decision unit:
- competing for limited resources (seats, time windows, route structure, vehicle quality),
- while also being able to cooperate with compatible reservations (same destination, timing, corridor), which in the system were materialized through agrupadores colaborativos.
This led to an implicit hierarchical structure:
- individual reservations →
- cooperative groupings (agrupadores) →
- selected pickups (high-quality assignments with minimal trade-offs)
What is described here as «low-propagation clusters» corresponds, in the original system, to stable pickup structures, meaning combinations of reservations that could be assigned together without generating significant downstream disruption.
The objective was not to globally optimize the full system in a single step, but to progressively structure the solution space, identifying stable combinations early and reducing the need for costly recomputation across the network.
At the same time, the system operated under three governing principles:
Hard constraints (capacity, punctuality commitments) could not be violated, so optimization was always subordinated to operational viability.
Objectives were not fixed; their relative importance evolved continuously based on system state.
No decision was isolated; each allocation reshaped the feasible space of all others, requiring explicit control of cascading effects.
Within this framework, the modules described below do not operate independently. They form a coherent decision logic:
- first defining a safe operating envelope (fragility and capacity),
- then establishing contextual priorities (dynamic pricing),
- then evaluating solutions (global utility),
- and finally structuring resolution through cooperative grouping and progressive stabilization of assignments.
The result is not a solver in the classical sense, but a centralized decision system that continuously navigates a constrained, dynamic, and propagation-sensitive allocation space under real operational pressure, approximating what would today be described as a multi-agent system, but implemented through deterministic and heuristic logic.
Fragility as a Capacity Signal
Fragility is modeled as an operational indicator of system risk under perturbation.
It is defined through two components:
a. Probability of Anomalies
The likelihood that the system will experience unexpected events, such as:
- no-shows
- late arrivals
- last-minute demand
- traffic disruptions
- execution inconsistencies
This probability depends on multiple contextual factors, including:
- seasonality and day type
- weather conditions
- demand volume and recent patterns
- prior-day anomalies and carry-over effects
This component can be estimated using standard machine learning approaches.
b. Propagation Probability
The likelihood that a local anomaly will generate cascading effects across the system.
This depends on the internal state, including:
- capacity saturation (vehicles close to full)
- congestion levels
- accumulated delays
- reduced flexibility in routing
- tight coupling between assignments
It was estimated using heuristics + ML for incremental learning.
2. Fragility as a Combined Measure
Fragility emerges from the combination of both components:
In practice:
- high anomaly probability alone is not critical if the system can absorb it
- high propagation sensitivity alone is not critical if anomalies are rare
But when both increase:
the system becomes fragile.
3. Capacity Management Layer
Fragility is not only monitored — it is used to drive capacity decisions.
This layer acts as an early warning and control mechanism:
- it identifies when and where the system is approaching unsafe conditions
- it signals the need for additional capacity or operational slack
This may include:
- adding extra vehicles (rented, reassigned units or dealing predictive maintenance)
- increasing buffer in routing decisions
- reducing tight coupling between assignments
- limiting aggressive optimization strategies
In other words:
fragility defines where the system needs reinforcement.
4. Role in a Mission-Critical System
This layer is fundamental because:
- the system operates under hard constraints (e.g. capacity, punctuality commitments)
- failure to meet these constraints is not acceptable
- optimization must always be subordinated to feasibility
Therefore:
Resource Pricing — Dynamic Pricing of Objectives
Before attempting to compute a routing or re-planning solution, the system must first determine what should be prioritized under the current operational state. In a system with multiple conflicting objectives, this cannot be handled through fixed weights. Instead, the system introduces a dynamic pricing mechanism, where price acts as the internal currency used to allocate operational effort.
In practical terms, the system must answer a simple question: how expensive is it, right now, to improve a given objective? This is modeled through demand-supply style marginal pricing functions. Each objective — travel time, fuel consumption, number of stops, direct trip versus transfer center usage, pickup punctuality, arrival punctuality, occupancy level, or compliance with vehicle-use policies — has a current price that depends on the state of the operation, not on a fixed rule defined in advance.
This matters because these objectives are frequently in conflict. Reducing travel time may increase fuel consumption. Minimizing the number of stops may worsen occupancy or force more transfers. Protecting pickup punctuality may harm arrival distribution at the parks. Sending a direct trip may improve service quality but consume scarce vehicle capacity that would otherwise stabilize the wider network. Even vehicle-type compliance can shift in importance: under normal conditions it may behave as a strong policy preference, while under disruption it may become less important than preserving punctuality or avoiding service failure.
The model therefore does not treat all objectives equally at all times. Some behave as rigid constraints, while others are semi-flexible and context dependent. At a given moment, delay may become very expensive because accumulated lateness is exhausting time buffers; fuel may remain relatively cheap because autonomy margins are still safe; reducing stops may or may not matter depending on route saturation; and using the transfer center may be either efficient or undesirable depending on current congestion and load distribution.
Formally, each objective i is associated with a demand curve Di(x) and a supply curve Si(x), where x is a state-pressure variable for that objective. A simple linear form is often sufficient:
Di(x) = ai + bix · Si(x) = ci − dix
When stronger nonlinear behavior is needed near critical regions, the same logic can be expressed with a quadratic form:
Di(x) = ai + bix + eix² · Si(x) = ci − dix − fix²
The current cutoff point is obtained by solving Di(x*) = Si(x*). This is trivial computationally: in the linear case it is a direct division, and in the quadratic case it is a standard second-degree equation. This makes the pricing layer very cheap to recompute, since it operates only on a small number of aggregate state variables before the combinatorial search begins.
This also greatly improves explainability. Instead of relying on opaque scoring, the system can express decisions in operational language: punctuality was prioritized because delay pressure had crossed its tolerance threshold; fuel was deprioritized because its current marginal cost remained low; direct trips were restricted because transfer-center usage was temporarily more efficient for preserving network stability. Once these prices are established, the downstream optimization becomes much cleaner, because candidate decisions are no longer compared through static abstract weights, but through current, state-dependent marginal costs.
Global Utility Evaluation and Stopping Condition
Once local utilities have been defined, any candidate solution can be evaluated through a single aggregated metric: global utility. Each assignment — routes, allocations, transfer decisions, or re-planning actions — produces gains in some objectives and losses in others, and these are combined into one comparable score.
This creates a unified framework for both mission-critical feasibility and continuous optimization. Hard constraints are modeled as prohibitive negative utility, effectively invalidating a solution. Examples include allowing passengers to travel standing, leaving committed passengers uncollected, violating seat capacity, or generating assignments that are operationally infeasible under route or vehicle restrictions. These are not treated as ordinary trade-offs, but as near-infinite negative outcomes that the system must avoid.
Soft or semi-flexible constraints are handled differently. Travel time, number of stops, transfers, fuel use, occupancy balance, or park-arrival distribution can all be improved or degraded with different marginal impacts depending on the current state. This allows the system to optimize continuously inside the feasible region, while still preserving mission-critical service commitments.
The main role of global utility is not to chase a theoretical optimum, but to measure how good or bad the current solution is at system level. As long as there is available time and computational budget, the system can continue improving the solution. But when decisions must be made quickly, or when operational or computational resources become scarce, the same metric provides a practical stopping condition: the system can stop once utility is high enough, or once further search is no longer worth the cost.
In that sense, global utility serves both as an optimization target and as a control signal under pressure. It allows the system to combine mission-critical feasibility with incremental optimization, always knowing whether the current solution is unacceptable, improvable, or already good enough to execute
Agent Resolution Through Cooperative Groups and Operational Stability Partitioning
At solution level, the problem was treated as a multi-agent allocation system in which each reservation behaved as an agent competing for scarce operational resources: vehicle quality, route structure, pickup quality, transfer avoidance, travel time, and arrival quality. Because these resources were limited, improving the assignment of one reservation could directly reduce the feasible quality of the assignments available to others. In that sense, the system was not only routing vehicles; it was continuously resolving competition for scarce service quality under hard commitments and dynamic constraints.
However, reservations were not always purely competitive. In many situations, they had strong incentives to cooperate. Compatible reservations sharing destination, timing, corridor, and vehicle fit could be combined into cooperative groups, meaning sets of agents that no longer needed to compete internally because they could be optimized jointly. A typical example was a set of passengers going to the same park and fitting naturally into a direct trip: once such a coalition existed, treating those reservations independently would only increase complexity and reduce utility. The first reduction of the problem therefore came from identifying where cooperation was more valuable than competition.
This created a hierarchical planning structure. At the lowest level were individual reservations. Above that, the system formed cooperative groups: sets of reservations that could be planned together because they fit into the same local operational decision. Above groups, the system created low-propagation clusters, meaning sets of groups that could be treated as relatively self-contained subproblems because their decisions were unlikely to destabilize the rest of the network. This was not classical clustering in the data-science sense; it was a form of operational stability partitioning.
The key criterion was not geography by itself, but expected propagation. A cluster was useful when its internal optimization could be carried out with low disruptive impact on other clusters. In practice, this could happen for more than one reason. Some clusters were operationally isolated, meaning they were far enough from others that their decisions had little effect outside the cluster. Others were locally dense or internally resilient, meaning they were close enough or sufficiently supported by nearby slack that local perturbations could be absorbed without forcing wider system-wide reconfiguration. In both cases, what mattered was not physical shape but stability of consequences.
This distinction is important because the underlying problem could not realistically be solved through direct global optimization. The operation involved a very large combinatorial space, multiple conflicting objectives, and continuous perturbations from no-shows, late sales, congestion, and changing vehicle availability. A single local change could propagate into timing, capacity, route feasibility, transfers, and park-arrival distribution. Because of that, the practical strategy was to break the problem into areas where decisions could be fixed sequentially with limited downstream damage, instead of attempting a single global maximum over the entire network.
Cluster construction was therefore heuristic by design. The system did not assume perfect mathematical separability. Instead, it estimated practical separability using operational heuristics, supported where useful by machine learning. These heuristics included spare capacity buffers inside the cluster, relative distance from other clusters, the free capacity of nearby clusters, and the estimated probability that local changes would propagate outward. The aim was not to prove independence, but to identify subproblems stable enough to be solved locally without creating unnecessary global recomputation.
Once clusters had been formed, planning proceeded sequentially by stability. The system first solved the most independent or most stable cluster and locked its best trip structure. It then moved to the next cluster with the lowest expected interference with the already fixed ones, often selecting the farthest or least coupled cluster in propagation terms. Then it repeated the process with the next one, and so on, gradually assembling the full plan. This sequencing mattered because it reduced the active search space step by step while minimizing the probability of having to undo previous decisions.
This made the approach computationally tractable in practice. Instead of searching globally over all reservations at once, the system solved the easiest and safest parts first, where local optimization was least likely to create cascades. Early decisions were therefore not merely convenient; they were deliberately taken from the most stable regions of the problem. That allowed the planner to lock useful structure early and postpone the most entangled cases until the end, when more context was already fixed.
A major reason this could be done quickly was the use of decision memory. The architecture did not start from zero every time a cluster had to be planned. During available processing time, the system continuously preprocessed plausible scenarios, stored useful decisions, and ranked alternatives under different objective regimes. As a result, when a cluster similar to a previously explored one appeared, the search was often close to direct: the system already had candidate trip patterns, promising assignments, and prior information about which configurations tended to work well under similar conditions.
This was especially powerful in stable clusters. Once a cluster had been classified as low-propagation, the search for its best trip configuration could be very fast because much of the ranking work had already been done in advance. Instead of generating all alternatives from scratch, the system reused knowledge from similar group compositions, similar route patterns, similar load structures, and similar objective priorities. In practice, this turned part of the problem from blind combinatorial search into informed retrieval plus local adjustment.
As planning progressed, the easiest clusters disappeared first. What remained at the end were the difficult residual cases: problematic clusters, competing coalitions, shared scarce vehicles, cross-cluster interference, borderline feasibility, and situations where improving one area could still destabilize another. These cases were precisely the ones with the highest propagation risk and the weakest local separability.
At that stage, the system no longer behaved as if a perfect optimum were required. It continued searching only while the expected gain justified the remaining time and computational effort. In other words, the residual hard zone was handled under the same global utility logic described earlier: if there was time and capacity, the system kept optimizing; if operational pressure required action, it executed the best sufficiently good solution found so far. This is what allowed the architecture to combine mission-critical feasibility with continuous optimization in a live, constraint-saturated environment.
This account describes a field-deployed system (2016–2017) and its architecture. The retrospective «pre-agentic» reading is a conceptual interpretation used to explain behaviour, not a description of the original code; the system was not an LLM-agent system, does not prove quantum advantage, and is not claimed to outperform current solvers.